|
Hi! 👋 I'm Leon, a Computer Science Ph.D. student at Stanford University. I'm grateful to be advised by Serena Yeung and Ludwig Schmidt at Stanford AI Lab. I was a research scientist intern at Meta Superintelligence Labs. Before Ph.D., I did my undergrad and worked at Nanyang Technological University, advised by Ziwei Liu. I've also worked with Alan Yuille and Zongwei Zhou at Johns Hopkins University. My research focuses on developing scalable frameworks for training and evaluating AI agents. I work on multimodal reasoning agents, data-efficient training methodologies, data collection pipelines, and practical architectures that enable agents to perform complex reasoning tasks. My interests span from foundational model development to building robust pipelines for agent training and evaluation. I'm passionate about bridging the gap between research and real-world applications of AI systems. Whether you're working on synthetic data, exploring collaborative research opportunities, or developing practical reasoning applications, I'd love to connect and discuss potential synergies. Email / Google Scholar / Semantic Scholar / Github / LinkedIn |

|
|
CVPR'26 J2A Workshop — Call for Papers!
|

|
|

|
Summary: A framework for multimodal chain-of-thought test-time scaling that enables a single unified model to reason, verify, and refine across multiple rounds. |
|
|
Summary: terminal-bench is a collection of tasks and an evaluation harness to help agent makers quantify their agents' terminal mastery. |

|
Summary: Train and test models on native-resolution images. Use mixed-resolution datasets to balance performance with computational resources, and maintain consistent resolution between training and inference to avoid misalignment issues. |

|
Summary: The first open-source model trained on public reasoning data to match DeepSeek-R1-Distill's performance through 1000+ systematic data curation/synthesis experiments. |

|
Summary: A large categorized dataset with 24+ million biomedical image-text pairs across multiple domains with expert-guided annotations. |
|
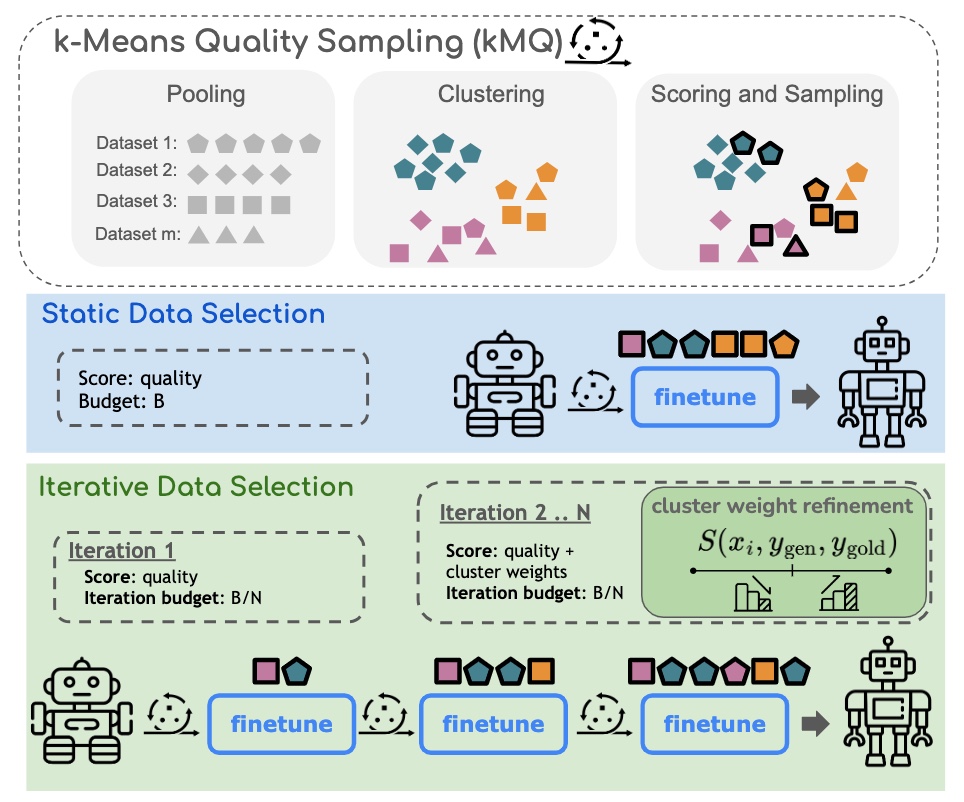
Summary: Prioritizing global data diversity over local instance quality for instruction data selection using k-means clustering iteratively. |
|
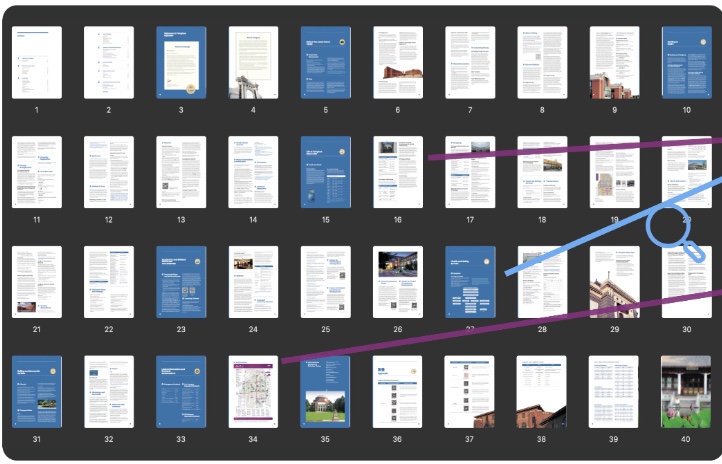
Summary: A challenging long-context multi-modal document understanding benchmark with 1,062 expert-annotated questions requiring cross-page reasoning. |

|
Summary: The first benchmark evaluating AI agents on evolving real-world websites with 1,050 human-written multihop tasks requiring long-range reasoning. |

|
Summary: An open-source multilingual model fine-tuned on human-reviewed safety instructions aligned with the Biden-Harris AI safety executive order. |

|
Summary: An extensive benchmark systematically analyzing generative data across visual recognition tasks with a novel CLER Score metric. |

|
Summary: The first large-scale multi-modal instruction tuning dataset with 2.8 million instruction-response pairs derived from images and videos. A model is trained on this dataset to achieve state-of-the-art performance on vision-language tasks. |

|
Summary: The first multimodal agent study to use natural language as communication medium for LLMs to coordinate multiple vision-language models for complex reasoning. |

|
Summary: Extended scene graph generation from static images to dynamic videos with unified panoptic understanding of objects and stuff. |

|
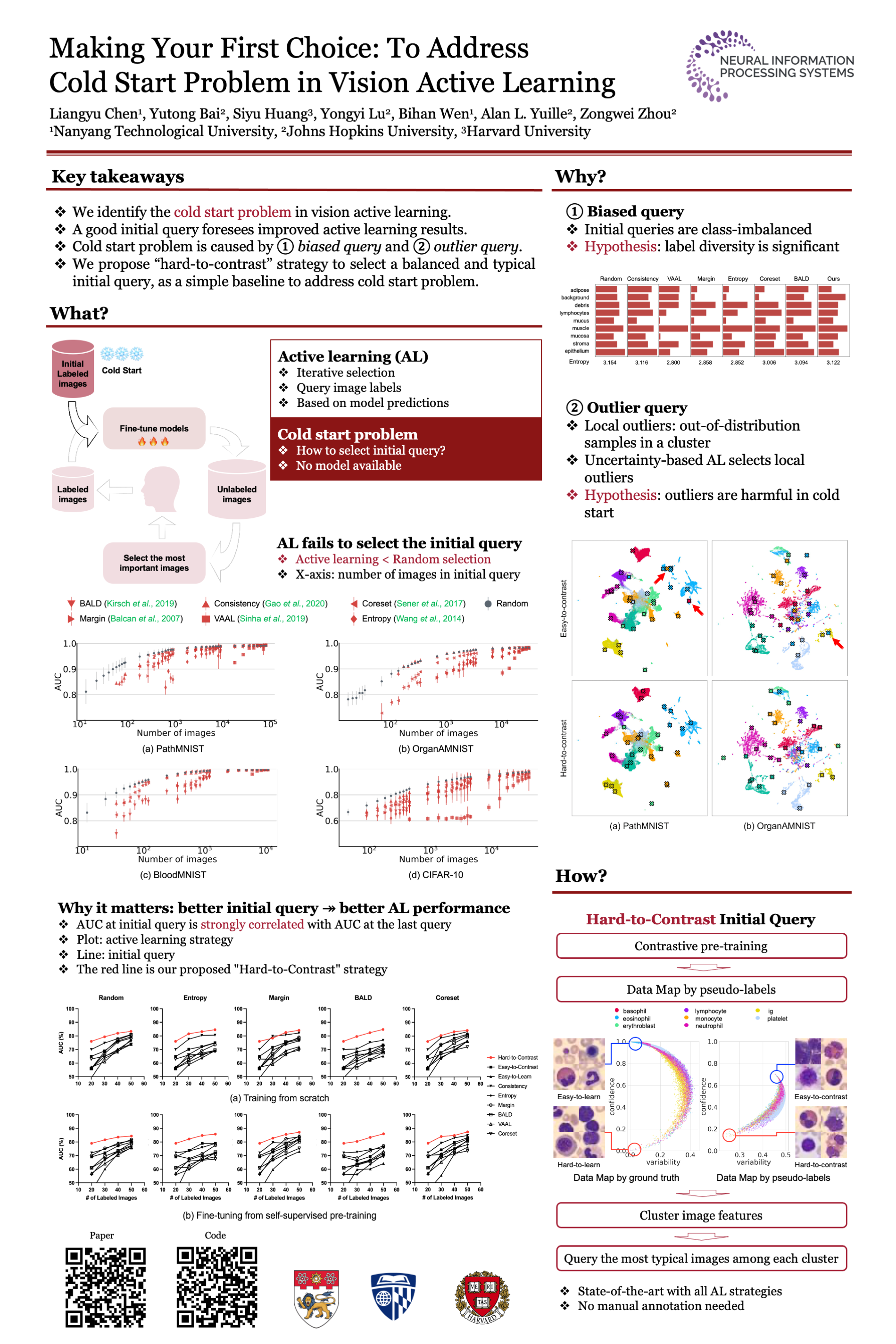
Summary: A systematic approach to solving the cold start problem in vision active learning using self-supervised contrastive features without labels. |

|
Summary: Modeling spatial and visual relationships among calcifications using graph convolutional networks for breast cancer diagnosis. |

|
Summary: A unified open-source framework specifically designed for model-based reinforcement learning research with modular components. |
{kind=link}
|
|
|
|